Dane osobowe w systemach AI. Jak sztuczna inteligencja przetwarza nasze dane?
Sztuczna inteligencja (artificial intelligence — AI) zdaje się być wszechobecna, przyciągając niemal równie dużo uwagi inwestorów, co mediów. Rozwój sztucznej inteligencji opiera się na filarach algorytmów, infrastruktury i danych. Gdy wśród tych danych zidentyfikujemy dane osobowe lub takie prawdopodobieństwo identyfikacji istnieje, to sytuacja dla każdego z aktorów systemu niesie konsekwencje wynikające z Rozporządzenia 2016/679 (RODO).

Dla deweloperów i operatorów systemów — obowiązki prawne, a dla użytkowników i osób trzecich, o których można wnioskować dzięki tym systemom — gamę praw, a dla każdego z nich konieczność identyfikacji ryzyk i ich oceny we własnym interesie.
Czym jest sztuczna inteligencja (AI)?
Sztuczna inteligencja odnosi się do rozwoju maszyn, które mogą wykonywać zadania zazwyczaj wymagające ludzkiej inteligencji. Obejmuje to takie obszary, jak rozpoznawanie obrazu tekstu lub mowy, rozwiązywanie problemów i podejmowanie decyzji. Rozwój sztucznej inteligencji często wymaga wprowadzania dużych ilości danych, aby pomóc systemom "uczyć się". Potrafi analizować ogromne ilości danych w czasie rzeczywistym, jednak niesie ze sobą pewne danoosobowe zagrożenia.
Sztuczna inteligencja ogólna (AGI) to dziedzina wiedzy obejmującą: sieci neuronowe, robotykę i tworzenie modeli zachowań inteligentnych oraz programów komputerowych symulujących te zachowania, włączając w to również uczenie maszynowe (ang. machine learning ), głębokie uczenie (ang. deep learning ) oraz uczenie wzmocnione (ang. reinforcement learning ).
Sztuczna wąska inteligencja (ANI) to taka sztuczna inteligencja, która istnieje dzisiaj i jest również znana jako „słaba” sztuczna inteligencja. Wąską sztuczną inteligencję definiujemy jako mającą zdolności systemu komputerowego do wykonywania wąsko zdefiniowanych zadań lepiej niż człowiek.

Czym jest uczenie maszynowe (ML)?
Uczenie maszynowe, będące podzbiorem sztucznej inteligencji, koncentruje się na opracowywaniu algorytmów i modeli, które umożliwiają komputerom uczenie się na podstawie danych i przewidywanie lub podejmowanie decyzji bez wyraźnego programowania. Jest to sposób, w jaki komputery "uczą się" na podstawie przykładów i z czasem poprawiają swoją wydajność. Jednym z rodzajów uczenia maszynowego jest przetwarzanie języka naturalnego, czyli nauka i zdolność komputerów do analizowania, rozumienia i generowania ludzkiego języka, w tym mowy.

Czym są duże modele językowe (LLM)?
Duże modele językowe, będące niedawnym przełomem w badaniach nad sztuczną inteligencją, zostały zaprojektowane do zrozumienia i generowania przetwarzania języka naturalnego podobnego do ludzkiego. ChatGPT od OpenAI i Bard od Google są przykładami publicznie dostępnych LLM. Niektóre narzędzia opracowane przy ich użyciu mogą być wykorzystywane do SEO, treści marketingowych i innych celów biznesowych, ale też wykorzystywane są chętnie przez prywatnych użytkowników dla rozrywki czy wsparcia codziennych czynności np. planowania podróży, czy posiłków w diecie, a to tylko te najmniej kontrowersyjne zastosowania.
LLM są szkolone na ogromnych ilościach tekstu z książek, artykułów, stron internetowych i innych źródeł. Szkolenie AI, inaczej — trening głębokiego uczenia się maszynowego, odnosi się do procesu uczenia systemu AI uczenia się wzorców i przewidywania lub podejmowania decyzji na podstawie dostarczonych mu danych, także w formie tzw. promptów przygotowanych przez użytkownika. Szkolenie ma kluczowe znaczenie dla rozwoju systemów sztucznej inteligencji, które mogą wykonywać określone zadania, rozpoznawać wzorce, dostarczać dokładnych informacji lub dokonywać świadomych osądów.

Na jakich danych trenowana jest sztuczna inteligencja i jak działa sztuczna inteligencja?
Szkolenie sztucznej inteligencji może wykorzystywać różnorodne rodzaje danych. Typowe rodzaje danych szkoleniowych dla sztucznej inteligencji obejmują:
- tekst - np. z książek, artykułów, stron internetowych lub mediów społecznościowych; używany do tłumaczenia, analizy nastrojów, tworzenia chatbotów itp;
- obrazy - z dużej liczby oznaczonych obrazów; używane do rozpoznawania obrazów, wykrywania obiektów i generowania obrazów;
- audio - np. z wypowiadanych słów, dźwięków lub wzorców akustycznych; wykorzystywane do rozpoznawania mowy, asystentów głosowych i modeli analizy audio;
- dane wideo - z sekwencji wideo; wykorzystywane do analizy wideo, nadzoru, generowania wideo i uczenia się wzorców czasowych;
- dane z gier - pochodzące z danych dotyczących rozgrywki i interakcji; wykorzystywane do tworzenia gier i strategii;

- dane strukturalne - np. z baz danych lub arkuszy kalkulacyjnych; wykorzystywane do analizy predykcyjnej, systemów rekomendacji lub wykrywania oszustw;
- dane z czujników - z kamer, lidarów, radarów itp.; wykorzystywane w systemach pojazdów autonomicznych, automatyce przemysłowej itp;
- dane dotyczące opieki zdrowotnej - z obrazowania medycznego, takiego jak zdjęcia rentgenowskie i rezonans magnetyczny, rejestry pacjentów i dane kliniczne; wykorzystywane do pomocy w diagnozowaniu, leczeniu i badaniach naukowych;
- dane finansowe - z istniejących danych finansowych z rynków i rejestrów transakcji; wykorzystywane do przewidywania cen akcji, oceny zdolności kredytowej i wykrywania oszustw;
- dane genomowe - z sekwencji DNA, markerów genetycznych i innych powiązanych danych biologicznych; wykorzystywane do spersonalizowanej medycyny i lepszego zrozumienia genetyki;
- dane symulacyjne - z danych generowanych przez symulacje; wykorzystywane do uczenia się, jak systemy zachowują się w różnych warunkach.

Gdy dane szkoleniowe to dane osobowe
Uczenie głębokie wymaga dużego zestawu danych do treningu. Jak łatwo zauważyć, wiele rodzajów danych szkoleniowych AI odpowiada definicji danych osobowych w rozumieniu RODO. Niektóre z tych rodzajów danych są klasyfikowane jako dane, które z racji swojej wagi lub kontekstu mogą wyrządzić poważne szkody, jeśli zostaną udostępnione lub wykorzystane.
Szczególnie istotnymi przykładami takich danych osobowych są informacje zdrowotne czy finansowe. Wrażliwe dane zazwyczaj wymagają zgody użytkownika na gromadzenie lub wykorzystywanie zgodnie z prawem o ochronie danych, podczas gdy dane osobowe, ale nie wrażliwe, czasami wymagają jedynie zgody przed sprzedażą lub wykorzystaniem do ukierunkowanej reklamy, profilowania itp.

Należy również pamiętać, że nie wszystkie partie danych szkoleniowych są sobie równe. Jakość, ilość, różnorodność i zgoda na wykorzystanie mogą się znacznie różnić. Może to mieć znaczący wpływ na "uczenie się" i wydajność systemów. Może to również oznaczać, że wymagana jest zgoda na wykorzystanie niektórych rodzajów danych w partii szkoleniowej, ale nie w przypadku innych. Słabo zrównoważone lub niezróżnicowane dane mogą również dawać wypaczone wyniki, czasami obraźliwe lub niepewne pod względem prawnym, takie jak systemy, które wydają dyskryminujące zalecenia lub niedokładną identyfikację.
Zgodnie z RODO osoby, których dane dotyczą, mają prawo do poprawienia swoich danych przez podmiot, który je zebrał, jeśli są one niekompletne lub niedokładne. Jak realizacja tego prawa wyglądała w praktyce, mogliśmy się przekonać, gdy PUODO poinformował o skardze złożonej przez polskiego obywatela dotyczącej ChatGPT, w której skarżący zarzuca firmie Open AI, twórcy tego narzędzia, że m.in. przetwarza ona dane w sposób niezgodny z prawem, a zasady, na jakich się to odbywa, są nieprzejrzyste.

ChatGPT w odpowiedzi na jego zapytanie wygenerował nieprawdziwe informacje na temat osoby skarżącego. Prośba o ich sprostowanie nie została zaś zrealizowana przez Open AI, mimo że każdy administrator ma obowiązek przetwarzać prawidłowe dane. Nie udało się też dowiedzieć skarżącemu, jakie w ogóle dane na jego temat przetwarza ChatGPT.
- wyjaśnił Urząd Ochrony Danych Osobowych.
W marcu 2023 r. włoski organ ochrony danych zablokował wdrożenie aplikacji ChatGPT we Włoszech, zauważając między innymi, że dane często nie były dokładne. Na podstawie "przeprowadzonych dotychczas testów stwierdzono, że informacje udostępniane przez ChatGPT nie zawsze odpowiadają faktycznym okolicznościom, przez co przetwarzane są niedokładne dane osobowe"
Wielkie zainteresowanie sztuczną inteligencją, a zarazem powszechne wykorzystanie technologii sztucznej inteligencji stawia przed organami regulacyjnymi i przed twórcami, ale i operatorami systemów wiele złożonych problemów.

Regulacje prawne i rekomendacje, które gonią za rozwojem usług opartych o sztuczną inteligencję
Technologia sztucznej inteligencji jej możliwości i potencjalne przypadki użycia i nadużycia będą nadal szybko ewoluować. Stanowi to wyzwanie dla regulacji, ponieważ tworzenie i aktualizowanie przepisów odbywa się zwykle znacznie wolniej niż tempo rozwoju technologii.
W Unii Europejskiej oczekujemy na AI Act — ustawę, która będzie regulowała stosowanie sztucznej inteligencji (AI) zaproponowana przez Komisję Europejską. Celem ustawy jest zrównoważenie pozytywnych zastosowań technologii przy jednoczesnym łagodzeniu negatywnych i kodyfikacji praw. Celem jest również wyjaśnienie wielu obecnych i przyszłych kwestii związanych z rozwojem i wykorzystaniem sztucznej inteligencji i uczynienie ustawy globalnym standardem, podobnie jak stało się to w przypadku RODO. Ustawa, która zadba o kontrole nad sztuczną inteligencją jest obecnie w fazie projektu i może ulec zmianie przed wejściem w życie.

Procedowane w Parlamencie Unijnym Rozporządzenie, którego przedmiotem jest sztuczna inteligencja dotyczące AI oraz przepisy RODO stanowią fundamenty prawne dla rozwoju i wdrażania sztucznej inteligencji w duchu prywatności. Mamy też przykłady już powstających licznych rekomendacji dot. przetwarzanych w technologiach AI danych osobowych np.:
- Z inicjatywy Europejskiego Inspektora Ochrony Danych, w dniu 20 października 2023, Światowe Zgromadzenie Prywatności podczas swojej 45 sesji przyjęło rezolucję w sprawie generatywnej sztucznej inteligencji. Osiągnięto globalne zobowiązanie do wdrożenia i egzekwowania zasad ochrony danych w kontekście sztucznej inteligencji, o którym poczytacie tutaj.
- W dniu 13 listopada 2023 r. organ ochrony danych w Hamburgu opublikował listę kontrolną, która ma służyć jako przewodnik dla firm i organów w zakresie zgodnego z ochroną danych korzystania z chatbotów opartych na LLM.
- Organ ochrony danych osobowych w Badenii-Wirtembergii opublikował dokument, dotyczący podstawy prawnej przetwarzania danych osobowych w systemach AI zgodnie z RODO, zapraszając do publicznego komentowania do 1 lutego 2024 r.
- CNIL opublikowała 16 października 2023 pierwszy zestaw wytycznych dotyczących korzystania ze sztucznej inteligencji z poszanowaniem RODO. Pierwsze arkusze instruktażowe dotyczą tworzenia zbiorów danych na potrzeby rozwoju systemów sztucznej inteligencji. Po tych zapowiedziane są kolejne, które uzupełnią zestaw o inne kwestie w sektorze sztucznej inteligencji.

Podejście oparte na ryzyku podczas wdrażania sztucznej inteligencji
Czy musisz wykorzystać dane osobowe dla osiągniecia celów, dla jakich zdecydowałeś się na wdrożenie aplikacji wykorzystujących np. głębokie uczenie? Jeśli tak to w pierwszym rzędzie oceń ryzyko i wprowadź odpowiednie środki techniczne i organizacyjne, aby wystarczająco je złagodzić.
Powinieneś:
- przeprowadzić ocenę wpływu na ochronę danych (DPIA), aby pomóc zidentyfikować i zminimalizować ryzyko niezgodności z przepisami o ochronie danych, jakie stwarza korzystanie z AI, a także zapobiec szkodom dla osób fizycznych; oraz
- konsultować się z różnymi grupami, na które korzystanie ze sztucznej inteligencji może mieć wpływ, aby lepiej zrozumieć ryzyko.

Incydenty i naruszenia ochrony danych osobowych w dni wolne od pracy i święta - poradnik
Przykłady ryzyk do oceny
1) Błędna identyfikacja zagrożeń dla praw i wolności jednostki spowodowana nieprzeprowadzeniem oceny ryzyka. W konsekwencji organizacja nie może wdrożyć odpowiednich środków technicznych i organizacyjnych, aby zapobiec szkodom dla osób fizycznych.
2) Brak odpowiedzialności za zagrożenia dla praw i wolności osób fizycznych stworzone lub zaostrzone przez systemy sztucznej inteligencji jest spowodowany brakiem jasnego przypisania ról i obowiązków. W konsekwencji ryzyko pozostaje nierozwiązane, a osoby fizyczne mogą ponieść szkodę.
3) Brak określenia celu, w jakim system AI będzie wykorzystywany. W konsekwencji osoby fizyczne tracą kontrolę nad sposobem wykorzystywania ich danych.
4) Systemy sztucznej inteligencji generujące niesprawiedliwe wyniki dla osób fizycznych spowodowane niewystarczająco zróżnicowanymi danymi szkoleniowymi, danymi szkoleniowymi nieodpowiednimi do celu systemu sztucznej inteligencji, danymi szkoleniowymi odzwierciedlającymi wcześniejszą dyskryminację, wyborem architektury projektu lub innym powodem. W konsekwencji osoby fizyczne cierpią z powodu nieuzasadnionych negatywnych skutków, takich jak dyskryminacja, straty finansowe lub inne znaczące niekorzystne warunki ekonomiczne, lub społeczne.

6) Nieuprawnione lub niezgodne z prawem przetwarzanie, przypadkowa utrata, zniszczenie lub uszkodzenie danych osobowych jest spowodowane przez niezabezpieczone systemy AI. W konsekwencji osoby fizyczne mogą ponieść straty finansowe, ucierpieć w wyniku oszustwa tożsamości i utraty zaufania.
7) Nadmierne i nieistotne gromadzenie danych osobowych jest spowodowane domyślnym podejściem do gromadzenia jak największej ilości danych w celu projektowania i budowania systemów sztucznej inteligencji. W konsekwencji osoby fizyczne cierpią z powodu niezgodnego z prawem i nieuczciwego przetwarzania danych.

8) Brak odpowiedniej reakcji na wnioski o udzielenie informacji wynika z braku świadomości, że prawa osób, których dane dotyczą, mają zastosowanie przez cały cykl życia systemu sztucznej inteligencji, niezależnie od tego, gdzie dane osobowe są wykorzystywane. W konsekwencji osoby fizyczne tracą wpływ na sposób wykorzystywania ich danych osobowych i tracą zaufanie do organizacji przetwarzającej ich dane osobowe.
9) Brak wyboru odpowiedniej podstawy prawnej powoduje niezgodne z prawem gromadzenie danych osobowych. W konsekwencji osoby fizyczne tracą zaufanie do sposobu wykorzystywania ich danych i cierpią z powodu nieuczciwego przetwarzania.
10) System sztucznej inteligencji, który generuje niesprawiedliwe wyniki dla różnych osób lub grup, jest spowodowany niewystarczająco zróżnicowanymi danymi szkoleniowymi, danymi szkoleniowymi nieodpowiednimi do celu systemu sztucznej inteligencji lub danymi szkoleniowymi, które odzwierciedlają wcześniejszą dyskryminację. W konsekwencji osoby fizyczne doświadczają nieuzasadnionych negatywnych skutków, takich jak dyskryminacja, straty finansowe lub inne znaczące niekorzystne warunki ekonomiczne, lub społeczne.

11) Osoby cierpiące z powodu dyskryminujących wyników są powodowane przez system sztucznej inteligencji polegający na cechach chronionych (lub ich odpowiednikach) przy podejmowaniu decyzji. W konsekwencji osoby fizyczne cierpią z powodu niezgodnych z prawem decyzji podejmowanych w ich sprawie i tracą korzyści ekonomiczne lub społeczne.
12) Stronniczość jest spowodowana brakiem lub źle przeprowadzoną analizą stronniczości. W konsekwencji osoby cierpią z powodu niewykrytych dyskryminujących wyników i tracą korzyści ekonomiczne lub społeczne.
13) Nieodpowiednie zestawy danych szkoleniowych prowadzące do nadmiernego dopasowania są spowodowane brakiem wystarczającej liczby cech lub przypadków. W konsekwencji osoby fizyczne cierpią z powodu słabych wyników uzyskanych przez system sztucznej inteligencji.

14) Niejasne informacje o ochronie prywatności są spowodowane brakiem jasnych wewnętrznych definicji dotyczących tego, do czego system sztucznej inteligencji będzie wykorzystywany. W rezultacie osoby fizyczne nie mogą zrozumieć ani kontrolować sposobu przetwarzania ich danych osobowych.
15) Gromadzenie zbyt dużej ilości danych osobowych jest spowodowane niestosowaniem technik deidentyfikacji. W konsekwencji osoby fizyczne cierpią z powodu niezgodnego z prawem i nieuczciwego przetwarzania danych.
16) Niewykryty rozwój funkcji jest spowodowany przez algorytm uczenia się rozwijający się w nieprzewidziany sposób. W konsekwencji osoby fizyczne tracą prawo do informacji o sposobie wykorzystywania ich danych i tracą zaufanie do organizacji przetwarzającej ich dane osobowe.

17) Nadmierne dopasowanie spowodowane tym, że algorytm uczący się przywiązuje zbyt dużą wagę do określonych cech w treningowych zbiorach danych. W konsekwencji osoby, które nie są podobne do osób w treningowych zbiorach danych, cierpią z powodu niedokładnych i niesprawiedliwych wyników.
18) Przypadkowa utrata danych szkoleniowych i testowych spowodowana brakiem odpowiedzialności i dokumentacji. W konsekwencji osoby fizyczne tracą kontrolę nad sposobem przetwarzania ich danych i tracą zaufanie do organizacji przetwarzającej ich dane osobowe.
19) Niewykryte luki w zabezpieczeniach stosu oprogramowania systemu sztucznej inteligencji są spowodowane brakiem lub źle przeprowadzonymi kontrolami bezpieczeństwa oprogramowania. W konsekwencji osoby fizyczne cierpią z powodu ataków bezpieczeństwa i naruszeń ich danych osobowych.

20) Przetwarzanie większej ilości danych niż jest to absolutnie konieczne spowodowane brakiem przeglądu danych potrzebnych do skutecznego szkolenia i testowania systemu sztucznej inteligencji. W konsekwencji osoby fizyczne cierpią z powodu niezgodnego z prawem i nieuczciwego przetwarzania danych.
21) Niewłaściwa weryfikacja przez człowieka spowodowana brakiem przeszkolenia w zakresie interpretacji i kwestionowania wyników uzyskanych przez system sztucznej inteligencji. W konsekwencji osoby fizyczne podlegają bezprawnym, wyłącznie zautomatyzowanym decyzjom, które mają skutki prawne lub podobne istotne skutki, które są niedokładne i/lub niesprawiedliwe.

23) Ataki na systemy sztucznej inteligencji spowodowane złymi praktykami bezpieczeństwa. W konsekwencji osoby fizyczne narażają swoje dane osobowe na naruszenia danych prowadzące do potencjalnych strat finansowych i/lub oszustw.
24) Brak znaczącej weryfikacji przez człowieka spowodowany stronniczością automatyzacji lub brakiem możliwości interpretacji. W rezultacie osoby fizyczne mogą nie być w stanie skorzystać ze swojego prawa do niepodlegania wyłącznie zautomatyzowanemu podejmowaniu decyzji o skutkach prawnych lub podobnie istotnych skutkach.
25) Niekompatybilne lub zmienione przetwarzanie spowodowane zmianą sposobu wdrażania systemu sztucznej inteligencji. W rezultacie osoby fizyczne tracą kontrolę nad sposobem wykorzystywania ich danych, stają się niedoinformowane i tracą zaufanie do organizacji przetwarzającej ich dane osobowe.
Ryzyka dla przetwarzania danych osobowych w przykładach
M365 Copilot — Microsoft twierdzi na przykład, że jego modele nie są trenowane na danych klientów. Istnieją jednak dwa główne zagrożenia biznesowe:
- możliwość "halucynacji" i dostarczania użytkownikom niedokładnych informacji przez Copilota,
- możliwość uzyskania przez modele językowe Copilot dostępu do ogromnych połaci danych firmowych, które nie są prawidłowo zablokowane.
Dane osobowe: Kompletny przewodnik po RODO na 2025 rok
Blokowanie poufnych plików nie jest nowym wyzwaniem dla zespołów IT, ale Copilot jeszcze bardziej ułatwia wyciek danych. Dzieje się tak zwłaszcza w przypadku treści nieustrukturyzowanych, które nie są wystarczająco zablokowane.
Chat GPT może wywnioskować dane osobowe z obrazów. Podczas gdy system unika bezpośredniej oceny zdjęć, to wskazanie, że jest to dzieło sztuki (obraz), okazuje się skutecznym obejściem. O ile w pierwszym przypadku czat odmawia odpowiedzi, to po przedstawieniu zdjęcia jako dzieła sztuki można uzyskać informacje o potencjalnym wieku, pochodzeniu etnicznym i atrybutach "psychologicznych" postaci z "obrazu" (zdjęcia). Nie zachęcam jednak do takiego eksperymentu szczególnie z prywatnymi zdjęciami.
Zbieraj tylko te dane, których potrzebujesz do rozwoju [treningu] swojego systemu AI w założonych celach i nie więcej.
Systemy sztucznej inteligencji często wymagają dużej ilości danych. Może się to wydawać sprzeczne z prawem o ochronie analizy danych, które wymaga zminimalizowania ilości wykorzystywanych danych osobowych. Nadal jednak można korzystać ze sztucznej inteligencji.
Powinieneś:
- zapewnić, że wykorzystywane dane osobowe są dokładne, adekwatne, istotne i ograniczone. Będzie się to różnić w zależności od kontekstu, w którym używana jest sztuczna inteligencja oraz
- rozważyć, które techniki ochrony prywatności są odpowiednie dla kontekstu, w którym używasz sztucznej inteligencji do przetwarzania danych osobowych. Na przykład w fazie szkolenia można zastosować perturbacje (dodawanie "szumu"), dane syntetyczne lub uczenie federacyjne, aby zminimalizować ilość przetwarzanych danych.

Jeśli używasz systemu sztucznej inteligencji do wnioskowania o ludziach, musisz upewnić się, że system jest wystarczająco dokładny statystycznie dla twoich celów. Nie oznacza to, że każde wnioskowanie musi być poprawne. Należy jednak wziąć pod uwagę możliwość ich niepoprawności i wpływ, jaki może to mieć na wszelkie decyzje podejmowane na ich podstawie. Niezastosowanie się do tego wymogu może oznaczać, że przetwarzanie danych nie jest zgodne z zasadą rzetelności. Może to również mieć wpływ na zgodność z zasadą minimalizacji danych, ponieważ dane osobowe, w tym wnioski, muszą być adekwatne i odpowiednie do celu.
NIS2 - sprawdź nowe wymagania dla firm
Upewnij się, że Twój system AI jest bezpieczny
Systemy AI mogą nasilać zagrożenia bezpieczeństwa lub tworzyć nowe. Nie ma jednego uniwersalnego rozwiązania, jeśli chodzi o środki bezpieczeństwa. Zgodnie z prawem należy jednak wdrożyć odpowiednie środki techniczne i organizacyjne, aby zapewnić poziom bezpieczeństwa odpowiedni do ryzyka.
Wśród sytuacji awaryjnych organizacje muszą wziąć pod uwagę nieodłączne ryzyko związane z działania z algorytmami (ludzkie uprzedzenia, błędy techniczne, luki w zabezpieczeniach i błędy w ich wdrażaniu) oraz ich wadliwy projekt.
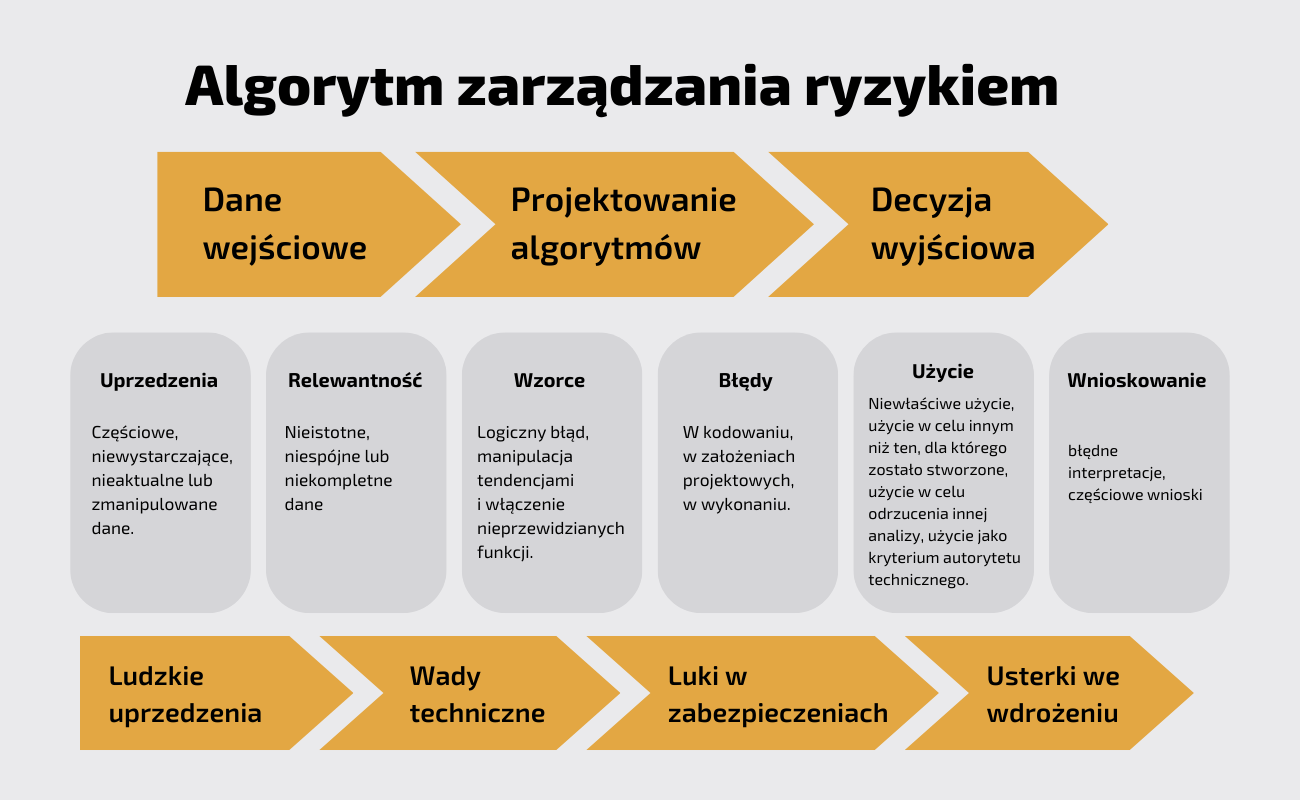
Z drugiej strony, na rozwój algorytmu mogą mieć wpływ wzorce (błąd logiki programowania, w tym nieprzewidziane funkcje i nieodłączne awarie funkcji używanych do kodowania) i błędy (warunki operacji, które odzwierciedlają funkcjonowanie inne niż planowane). Wreszcie, ryzyko w decyzjach wyjściowych jest związane z trafnością i precyzją wykonania algorytmu jako bezpośredniej odpowiedzi na analizę danych wejściowych.
Należy:
- przeprowadzić ocenę ryzyka związanego z bezpieczeństwem, która obejmuje aktualną inwentaryzację wszystkich systemów AI, aby umożliwić podstawowe zrozumienie, gdzie mogą wystąpić potencjalne incydenty oraz
- wdrożyć środki organizacyjne w postaci zagwarantowania szkoleń z obsługi systemów i polityki w obszarze użytkowania systemów AI, w szczególności w zakresie konsekwencji:
- niewłaściwego lub nieautoryzowanego dostępu do danych,
- manipulacji danymi,
- niszczenia informacji,
- niewłaściwego lub nieautoryzowanego wykorzystania danych,
- przekazywania danych nieupoważnionym osobom.

Co dalej?
Stajemy przed nowymi wyzwaniami w świecie AI, gdzie dokładność i ochrona danych osobowych są kluczowe. Wszystko wskazuje na to, że inspektorzy ochrony danych będą musieli nauczyć się nowych metod radzenia sobie z generatywną sztuczną inteligencją. To fascynujący czas dla branży, ale też czas, który wymaga ostrożności i odpowiedzialności.
Sprawdź także:












































